
Valódi tartalom-e a CSS content?
A cikk témái:
Figyelmeztetés: Ezt a cikket évek óta nem frissítettem, ezért elavult információkat is tartalmazhat.
Gyorsan leszögezem, hogy a címben feltett kérdésre az én határozott válaszom az, hogy nem. Nem egyenértékű tartalom a HTML kódba elhelyezett tartalom azzal a tartalommal, amit a CSS content nevű tulajdonságával illesztünk be a weboldalba. Ebben a cikkemben arra szeretnék rávilágítani, hogy miképpen befolyásolja mindez a weboldal akadálymentességét.
Mi az a beillesztett tartalom?
Már a CSS 2 szabvány is lehetőséget biztosított arra, hogy úgynevezett beillesztett tartalmat (generated content) jelenítsünk meg a weboldalon. A szabvány úgy fogalmaz, hogy a beillesztett tartalom olyan tartalom, ami nem a dokumentum fából jön
. Magyarul olyan tartalom, ami nem a HTML jelölőelemeivel van definiálva, hanem a CSS bizonyos tulajdonságainak segítségével.
A beillesztett tartalom jellegzetesen egy adott HTML jelölőelem tartalma előtt vagy mögött jelenhet meg, úgynevezett pszeudoelemekben. A CSS két pszeudoelemet biztosít erre a célra. A :before pszeudoelem kerülhet a kiválasztott HTML jelölőelem tartalma elé, az :after pedig mögé. A pszeudo elnevezés arra utal, hogy nem valódi elemekről beszélünk (ellentétben a HTML jelölőelemeivel), hanem fikcionális elemekről. Mindez abban is megnyilvánul, hogy a pszeudoelemek (a beillesztett tartalmukkal együtt) nem szerepelnek az oldal objektumait tartalmazó hierarchikus modelben, a DOM fában sem. Jelenlétük kizárólag a megjelenéshez kapcsolódik.
Megjegyzés: a CSS 3 kiválasztókról szóló szabványában az említett pszeudoelemek szintaktikája annyiban módosult, hogy egy helyett, két darab kettőspontot használunk. Vagyis ::before és ::after az új írásmód. Sajnos ezt a régebbi böngészőprogramok nem ismerik, így még ma is sokan a CSS 2 szerinti szintaktikát használják. Ebben a cikkben én is így teszek.
A pszeudoelemek beillesztett tartalmát a CSS content nevű tulajdonságával definiálhatjuk. A legegyszerűbb esetben ez valamilyen fix szöveg lehet, de a szabvány egyéb tartalmat is megenged.
Jöjjön egy példa az eddig leírtak illusztrálására.
Nem állítom, hogy életszerű a példa, sőt azt mondanám, hogy kifejezetten kerülendő, de szerintem segít megérteni a beillesztett tartalom körüli akadálymentességi anomáliákat.
Tételezzük fel, hogy a weboldalunk HTML kódjában egy listát definiálunk, ami mondjuk versenyzők neveit tartalmazza. A versenyzők nevét tartalmazó li listaelemek class attribútumába annak a településnek a rövidítését írjuk bele, ahonnan az adott versenyző érkezett.
<ul>
<li class="bud">Kis Péter</li>
<li class="sop">Nagy Anna</li>
<li class="bud">Kovács Ferenc</li>
</ul>
Ezt követően a CSS-t bízzuk meg azzal, hogy minden versenyző mögé illessze be a város nevét. Vagyis olyan CSS kiválasztókat írunk, ami az osztálynevekkel elkülönített li elemek tartalma mögötti pszeudoelemekre hivatkozik. Ezeknek az :after pszeudoelemeknek a beillesztett tartalmát, vagyis egy szóközt, és a zárójelek közé írt város nevét a content segítségével definiáljuk.
li.bud:after {
content:' (Budapest)';
}
li.sop:after {
content:' (Sopron)';
}Ha ezek után megnyitjuk az oldalt egy böngészőben, akkor a felsorolt versenyzők neve mellett zárójelben megjelenik a városuk neve is, ahogyan azt a következő kép is mutatja:
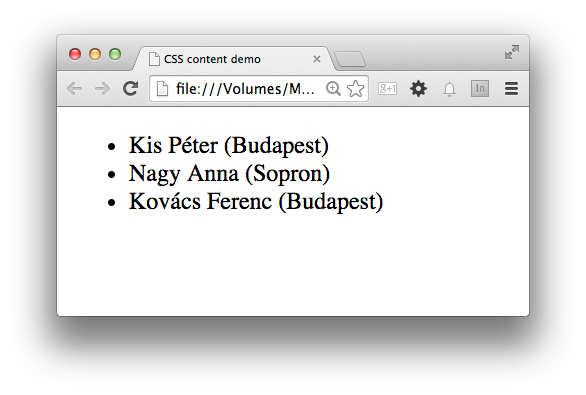
Azt gondolhatnánk, hogy elértük a célunkat, hiszen a felhasználóink most már elolvashatják azt is, hogy a versenyző honnan érkezett. A felhasználóinkat pedig amúgy sem érdekli (miért is érdekelné), hogy a városnevek esetleg CSS-ből beillesztett tartalmak.
Azonban ne hagyjuk magunkat becsapni a látványtól. Megoldásunk közel sem akadálymentes. Több probléma is van vele.
Másolhatósági és kereshetőségi problémák
Felhasználóink egyik csoportja akkor fog meglepődni, amikor valamilyen okból kifolyólag úgy dönt, hogy a versenyzői listát átmásolná magának egy szövegszerkesztőbe, vagy esetleg egy prezentációs diára. A szövegszerkesztőkben megszokott módon kijelöli a listát, de meglepetésére a városneveket képtelen kijelölni. Az alábbi képen az látszik, hogy a kijelölésben bizony csak a versenyzők neve lesz benne, a városuk nem.
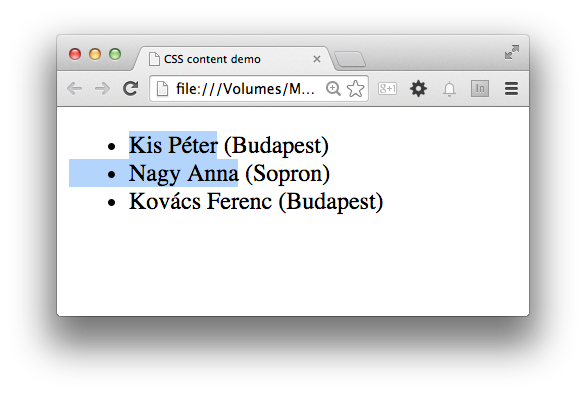
Ha ezt a felhasználó nem is venné észre elsőre, akkor arra bizonyára felfigyel majd, hogy a vágólapra kimásolt, majd onnan beillesztett szöveg is hiányos. Oda is csak a nevek másolódnak.
Megjegyzem, ezzel az akadállyal nem mindegyik böngészőben szembesülünk. Cikkem írásakor az Internet Explorer 9, 10 és 11 például maradéktalanul átmásolta a tartalmat, bár a kijelölés ott sem volt egyértelmű (a városokat betűnként nem lehetett kijelölni). Viszont az Internet Explorer korábbi verzióiban, a Chrome, a Firefox, a Safari, és az Opera legfrissebb verzióiban a pszeudoelemek beillesztett tartalma egyátalán nem jelölhető ki, és nem másolható a vágólapra.
Hasonló problémával szembesülnek azok a felhasználók is, akik a böngészőprogram beépített keresőjével keresnének valamilyen szóra az oldalon belül. Hiába írják be mondjuk azt, hogy Budapest
, nem kapnak találatot, pedig a szó kétszer is szerepel az oldalon. Ennek oka ismételten az, hogy a böngészőprogram csak azt tekinti valódi tartalomnak, ami a DOM-fában szerepel.
Abban nem foglalnék állást, hogy a böngészők részéről ez a viselkedés helyes-e vagy sem, viszont a probléma létezik.
Felolvassák-e a képernyőolvasó programok?
A web akadálymentesség látássérülteket érintő aspektusából tekintve talán ez a legfontosabb kérdés. Sajnos a válasz azonban erre sem egyértelmű.
Kezdjük azzal, hogy a CSS szabvány alapján elvileg fel kell-e olvasnia a képernyőolvasó programnak a CSS-ből beillesztett tartalmat? Szerintem igen.
A weboldal nem csak látható című cikkemben már kifejtettem, hogy amikor a weboldal CSS megjelenésről beszélünk, akkor ez alatt nem csak a képernyőn megjelenő vizuális megjelenést értjük, hanem a hallható, sőt a Braille-kijelzőkön keresztüli tapintható megjelenést is. A beillesztett tartalmakhoz szükséges pszeudoelemeket, valamint azok content tulajdonságát a CSS minden általa ismert médiatípusra engedélyezi, beleértve a képernyőolvasós auditív megjelenést is. A pszeudoelemek megjelenése képernyőolvasó esetén például azt jelenti, hogy a benne lévő beillesztett tartalom a valódi HTML elem tartalma előtt vagy után hangozzon-e el.
Példánkhoz visszatérve, egy képernyőolvasó programnak elvileg így kellene felolvasnia az első listaelemet:
listajel Kis Péter bal zárójel Budapest jobb zárójel
A CSS szabvány szerint tehát az a képernyőolvasó program jár el helyesen, amelyik felolvassa a beillesztett tartalmat. Kivéve, ha ezt kifejezetten nem tiltjuk meg neki, amire a szabvány - szintén csak elvileg - több lehetőséget is biztosít.
Ez volna az elv, de ezzel szemben mi a valóság?
Van olyan képernyőolvasó, amelyik felolvassa a beillesztett tartalmat, és van olyan is amelyik nem. Pontosabban fogalmazva, van olyan képernyőolvasó, amelyik bizonyos böngészőprogramokkal használva felolvassa, míg más böngészőprogramokkal nem olvassa fel. Vagyis a képernyőolvasók ezen képessége - mint sok egyéb esetben - a böngészőprogram által nyújtott információktól is függ.
A gyakorlatban sajnos ma még azt sem tudjuk szándékosan befolyásolni, hogy bizonyos beillesztett tartalmakat semmiképpen ne olvasson fel az a képernyőolvasó, még akkor se, ha ő egyébként ezeket képes lenne felolvasni. Például a speak:none; CSS szabály még egyik képernyőolvasóban sem támogatott.
Mindebből az a tanulság, hogy soha ne számítsunk arra, hogy a beillesztett tartalom akadálymentesen eljut a vak felhasználókhoz.
A beillesztett tartalom tulajdonképpen megjelenés
A CSS anno pont azért jött létre, hogy a weboldal tartalmát és a megjelenéseit élesen szétválaszthassuk. A szétválasztás elve alapján a tartalmat kizárólag a HTML, a megjelenést kizárólag a CSS definiálhatja.
Tehát bármilyen furcsán is hangzik, a CSS content - bár szó szerinti fordításban tartalom - nem tartalom, hanem megjelenés!
Az is fontos, hogy a CSS a HTML-re ráépülő réteg. Tehát ha leválasztjuk róla, akkor a megjelenés ugyan nem lesz szép, de az oldal tartalmához maradéktalanul és akadálytalanul hozzá kell férnünk.
Egy weboldal tartalmát a felhasználónak akkor is meg kell értenie, ha a CSS nem elérhető. Vagyis az oldal megértéséhez szükséges, kritikusan fontos tartalmat csak a HTML-ben szabad elhelyezni!
A CSS által beillesztett tartalom tehát valami olyasmi, ami a valódi tartalmat pusztán kiegészítheti, segítheti, de semmiképpen sem pótolhatja. Használatával bizonyos mértékig növelhető a felhasználói élmény.
Amikor a CSS-ből szeretnék tartalmat beilleszteni, akkor mindig tegyük fel magunknak azt a kérdést, hogy amit a content tulajdonsághoz írnánk, az vajon kritikus-e az oldal megértése, használata szempontjából, vagy sem? Vagy úgy is fogalmazhatunk, hogy ha a felhasználó esetleg nem fér hozzá ehhez a tartalomhoz (a korábban említett problémák bármelyike folytán), akkor vajon elesik-e valamilyen fontos információtól? Ha a válaszunk igen, akkor az adott tartalomnak a HTML kódban, vagyis a valódi tartalomban is feltétlenül szerepelnie kell.
Ez nagyban hasonlít a képek használatára. Egy adott képet elhelyezhetünk a HTML kódba is (az img jelölőelemmel), de a CSS kódba is, például háttérképként (a background-image tulajdonsággal). Ha a kép lényeges, vagyis tartalmilag kritikus, akkor mindenképpen a HTML kódban a helye. Mégpedig úgy, hogy az alt attribútum segítségével a kép tartalmát szövegesen is megadjuk. Ha viszont kizárólag az oldal esztétikáját, vizuális hangulatát hivatott befolyásolni, akkor mehet a CSS-be. Utóbbi esetben az a felhasználó, aki technikai vagy biológiai akadályozottságból következően ezeket a képeket nem látja, az az oldal tartalmát ettől függetlenül még tudja értelmezni, és használni.
Miért is nem jó a példánk?
Visszatérve a versenyzős példánkhoz, megállapíthatjuk, hogy azért hibás, mert igenis kritikus információ, hogy a versenyző honnan érkezett. Vagyis a városok nevét a HTML kódba kell elhelyeznünk, és nem szabad a CSS-sel beillesztenünk.
A következő példa kicsit határeset, bár én hajlok arra, hogy alkalmazás szempontjából ez is rossz.
Tételezzük fel, hogy a weboldalunkon minden letölthető fájl mögé ki szeretnénk írni azt, hogy az adott fájl milyen formátumú. Ehhez trükkösen felhasználhatjuk a CSS úgynevezett attribútum kiválasztóját, ami kiválasztja azon linkeket, amelyek href attribútuma mondjuk a .pdf szövegre végződik, és ezekhez beillesztünk egy (PDF dokumentum)
tartalmú szöveget.
a[href$=".pdf"]:after {
content:' (PDF dokumentum)';
}
A kérdés az, hogy ez a tartalom kritikus-e, azaz minden felhasználónak joga van-e értesülni arról, hogy a letöltendő fájl milyen formátumú. Szerintem igen, és ebből következően ennek a tartalomnak is a HTML-ben a helye. A dolog azért határeset, mert joggal mondhatja egy fejlesztő, hogy ez az információ csak egy kiegészítő információ, és ha majd a felhasználó letöltötte a fájlt, akkor úgy is megtudja formátumát
. Az olvasóra bízom, hogy melyik álláspont mellé áll.
Kép is lehet beillesztett tartalom
Ha már a képekről volt szó, fontos megemlíteni, hogy a CSS content tulajdonság értéke, vagyis a beillesztett tartalom nem csak szöveg, hanem kép is lehet. Például így:
li:after {
content:url('kep.png');
}
Mivel az így beillesztett kép szöveges tartalmát itt a CSS-ben nem tudjuk megadni, ezért egyértelmű, hogy ez a kép csakis a vizuális látvány szempontjából lehet érdekes. Hasonlóan a CSS háttérképekhez, valódi tartalmat ez sem hordozhat.
Egyébként a képernyőolvasó programok ezt a képet nem is említik. Egyedül talán a VoiceOver olvassa be azt, hogy kép
. De ezzel az információval ugyebár nem sokra megy a látássérült felhasználó.
Amikor a generált ikon sem akadálymentes
Sajnos mindezt sok honlapon abszolút nem veszik figyelembe. Igen elterjedt például a CSS-ből generált ikonok használata, jellemzően így:
a.facebook:after {
content:url('facebook_icon.png');
}
Egyértelműen nem akadálymentes megoldás, ha a HTML kódban ehhez csak ennyi társul:
<a href="http://www.facebook.com/valaki" class="facebook"></a>Ez ugyanis tartalmilag egy teljesen üres link! Fogalma se lesz annak a felhasználónak, aki képernyőolvasót használ, vagy a CSS-t nem éri el, hogy a link mit csinál, hova visz.
Ha mindenképpen ragaszkodunk a CSS-ből beillesztett ikonhoz, akkor az akadálymentes megoldás erre csak az lehet, ha a link nem üres, hanem tartalmazza a Facebook szót, mégpedig valamelyik vizuális elrejtési technikát alkalmazva. Mondjuk így:
<a href="http://www.facebook.com/valaki" class="facebook"><span class="vizualisrejtes">Facebook</span></a>
alt tulajdonság a CSS-ben?
A CSS4 pszeudoelemek szerkesztői piszkozatába bekerült egy CSS-ben megadható alt tulajdonság, ami a legutolsó példa akadálymentességét így oldaná meg:
a.facebook:after {
content:url('facebook_icon.png');
alt:'Facebook';
}
Ezzel az új tulajdonsággal kapcsolatban azonban még annyi a vita és a nyitott kérdés, hogy simán megtörténhet, hogy az egészből nem lesz semmi. Bennem például az a kérdés merült fel, hogy ennyi erővel az összes CSS-ben definiált háttérképhez is kellene egy ilyen alt tulajdonság, hiszen sajnos nagyon sok weboldalnál funkcionálisan fontos képeket tesznek a háttérbe, amit a képernyőolvasó programok nem érnek el.
Érdekesség, hogy a Safari 9.0 böngésző a VoiceOver képernyőolvasóval már natívan támogatja ezt az alt tulajdonságot.
Frissítés (2020. március): Az említett alt tulajdonság végül kikerült a CSS szabvány tervezetéből. A CSS Generated Content Module Level 3 szerkesztői piszkozatában jelenleg egy olyan szintaktika terv szerepel, aminél az alternatív szöveget egy / karakter után lehet majd megadni. A példánk elvben így nézne ki ezzel a szintaktikával:
a.facebook:after {
content:url('facebook_icon.png') / "Facebook";
}
A CSS listajelek is beillesztett tartalmak
Talán feltűnt, hogy versenyzős példánk képernyőolvasós idézeténél a listajel
szó is szerepelt. Nem véletlen, hiszen ha jobban belegondolunk, akkor a listajeleket is a CSS illeszti be az oldalra. Ha tetszik, akkor ez is egyfajta beillesztett tartalom, és mint ilyen, igaz rá minden, ami eddig a cikkben megállapítást nyert. Például az, hogy a listajel sem valódi tartalom.
A list-style-type tulajdonsággal tudjuk meghatározni a listajel megjelenési típusát. Ez tipikusan vizuális megjelenési tulajdonság, hiszen kizárólag a vizuális dizájn szempontjából van annak szerepe, hogy a listajel például teli kör, vagy üres kör, esetleg négyzet. Éppen ezért a CSS szabvány a list-style-type tulajdonságot csak a vizuális médiumok esetén értelmezi. Ugyanez igaz az egyedi képes listajelnél is, amit a list-style-image tulajdonsággal definiálhatunk.
Felmerülhet, hogy a sorszámozott listáknál is ugyanez a helyzet? Talán furcsa, de igen.
Szemléltetésképpen alakítsuk át a versenyzős példánkat úgy, hogy a versenyzők nevei sorszámozott listában - vagyis ul helyett ol jelölőelemben - legyenek:
<ol>
<li>Kis Péter (Budapest)</li>
<li>Nagy Anna (Sopron)</li>
<li>Kovács Ferenc (Budapest)</li>
</ol>
A korábbi példában lényegtelen volt, hogy a versenyzők felsorolása milyen alapon történt. Mivel az ul elemet alkalmaztuk, ezért a sorrendnek nem volt szerepe. De a most átalakított példánk már lehet, hogy a verseny végeredményét tartalmazza, vagyis azt, hogy az első helyen Kis Péter végzett.
A list-style-type segítségével itt is meghatározhatjuk, hogy beillesztett sorszám milyen megjelenésű legyen. Ha például nagybetűs római számokkal szeretnénk látni a listát, akkor ezt írjuk:
ol {
list-style-type:upper-roman;
}
Ez azonban ismételten csak vizuális dizájn! Valódi tartalma a listasorszámnak sincs. Mindegy, hogy milyen szám, vagy milyen karakter jelöli a sorrendet, a lényeg, hogy Kis Péter lett az első, Nagy Anna pedig a második. A valódi tartalom megint a HTML kódban van, hiszen az ol elem használatával szemantikailag definiáltuk, hogy a lista sorrendje fontos, és az első listaelem, vagyis Kis Péter az első. Ezt a CSS-től teljesen függetlenül, minden rendszer érteni fogja.
Érdekes viszont, hogy a képernyőolvasó szoftverek ettől függetlenül ha tehetik, akkor felolvassák a listasorszám CSS-ben definiált stílusát is. Ez tulajdonképpen rendben is van, hiszen ezzel segíthetik a vak felhasználót. Ugyanakkor látnunk kell, hogy a beillesztett tartalom itt is csak kiegészítő célú.
Létezhetnek olyan kivételes esetek, amikor listasorszám több, mint puszta vizuális dizájn. Gondoljunk például jogi dokumentumokra, ahol a pontos sorszám, sőt akár annak pontos formátuma is hivatkozási alap lehet. Ekkor a sorszám valódi tartalom, és nem dizájn, vagyis kénytelenek leszünk a sorszámot is beleírni a HTML kódba.
Létezik valami hasznos alkalmazása a beillesztett CSS content-nek?
A fentiek tükrében nem sok maradt, de azért mutatok egy olyan példát, amikor érdekes módon a content kifejezetten akadálymentességi szerepet tölt be.
A weboldal kinyomtatásakor a linkek tulajdonképpen értelmezhetetlenek. Az a felhasználó, aki kézbe veszi a weboldal kinyomtatott verzióját, maximum aláhúzott szövegeket lát, de azt, hogy a szövegben elhelyezett linkek milyen weboldalakra hivatkoznak már nem tudja meg. Holott a linkek URL címei ott vannak a HTML kódban.
Csináljuk azt, hogy a link URL címét a nyomtatáskor a CSS beilleszti az oldalba. Ezt úgy érhetjük el, hogy a content tulajdonság értéke az attr() függvény segítségével megkaphatja a kapcsolódó HTML jelölőelem tetszőleges attribútumának aktuális értékét is. Ha a kérdéses linkek után, beillesztett tartalomként, zárójelben megjelenítjük a link href attribútumának értékét, akkor a felhasználó már akadálymentesen hozzájut a link URL címéhez.
@media print {
a[href]:after {
content:' (' attr(href) ')';
}
}Összegzés
Talán sikerült összegyűjtenem azokat az érveket, amelyek a bevezetőben tett állításomat alátámasztják. Akadálymentesen elérhető, valódi tartalom az, ami a HTML kódban, illetve ennek következtében a DOM-fában is szerepel. A beillesztett CSS tartalom nem ilyen.
Szeretném jelezni, hogy a cikkből szándékosan mellőztem a manapság egyre népszerűbb ikon fontok használatát. Ezeknél is a content tulajdonság van a fókuszban, de mivel további akadálymentességi problémák is felmerülnek, ezért az ikon fontok akadálymentességét egy külön cikkben mutatom be.